
几天前霍炬老师在群里推荐了一个叫“高分子怪物”的 Blog,当时也没打开看,只知道是个新浪博客。当天晚些时候,我看到另外几个朋友也在讨论这个 Blog,还很热烈的样子。看来大家都被吸引住了,于是我也点开看了看,发现他讲的是美国最高法院以及美国的法律系统。
我对美国最高法院有些兴趣,之前在单向街书店闲逛的时候看到一本叫做《美国最高法院通识读本》的书,后来在亚马逊上买到了 Kindle 版。这本书不算长,读完之后算是对美国最高法院有了点基础认知。由于近两年观赏的美剧里有不少政法剧,我不介意再了解深一些,所以就想着花多一些时间看看这个被好多人推荐的 Blog。
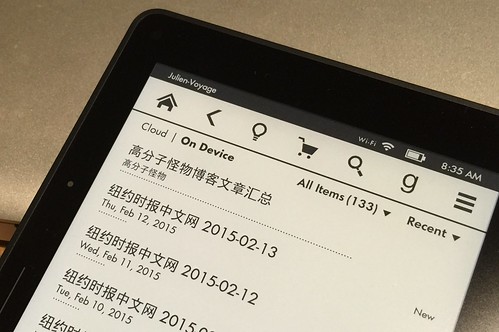
只看了两篇文章,我就已经觉得值得把所有文章都读一遍。这个时候我十分想把这些文章弄到 Kindle 上去,原因有二:首先是大块的阅读时间不多,然后是不喜欢在液晶屏上看长文。于是,我决定自己动手做一个电子书。
一般来说,我自己做电子书的话会用 HTML 文件及格式。首先将每个章节单独保存为一个 HTML 文件,然后再用一个 Index.html 索引文件把它们全部链接起来。这实际上也是上个世纪九十年代的网络电子书的处理方式,如今的互联网上还能找到一些蛛丝马迹。但我不是念旧啊,我只是觉得这样子做电子书比较容易生成目录而已。
问题在于这位作者已经写了一百一十六篇文章,这个数量不算少。按照我的传统办法,我需要将这一百来篇文章一一下载回来,然后按照顺序做个索引文件出来。这些事情做完,我估计花掉的时间可能还不比直接在网上读完来的少。而且我觉得这种枯燥无味的事情太浪费生命,不应该也不值得自己亲自做。所以,当时我的情况是:1,我想读完这些文章;2,我想在 Kindle 上读;3,我不想浪费时间亲手做电子书。
稍微想了一下,这种事情写个脚本就解决了嘛。
我不是程序员,而且有一两年没亲手写 Python 了,我知道这个时候写一个脚本所花费的时间要远远多于下载一百多篇文章。但我认为写脚本这件事情是值得的,世界这么大,好文章不只“高分子怪物”一人在写呀。要是写出这么一个脚本来,可以省下很多时间呢。
于是开写。
经过一个下午的研究以及晚上的调试,第一个可用的版本已经发布出来,大家可以在 Github 上看到并下载到源代码。
原理很简单,如果不乐意看代码,那就看我的唠叨吧:
第一步,找到这个人的 Blog User ID(以下简称 UID)。在新浪博客体系里,UID 是唯一的,而且几乎所有的 URL 都与 UID 多多少少有关系。有了 UID 之后,很多事情就可以做到了。
第二步,找到全部文章列表。掌握了 UID,就能顺利地找到文章列表清单。即便是只有几篇文章,第一页也是存在的。所以先分析第一页,抓到本页所有文章 ID 先,然后再看看这个人总共有多少篇文章。由于文章列表每一页要展示五十篇文章,算一下就知道总的页数是多少。循环一下,就能把所有文章的 ID 抓取到。
第三步,下载全部文章。因为有了文章 ID,所以构建文章 URL 易如反掌。这一步基本上就是一个循环,将所有的文章下载到本地即可。下载的时候稍微处理了一下,只保存作者的文字,页面内其他的元素(广告、评论、导航什么的)全部舍弃。最后再生成一个 index.html 作为主控文档,它将所有的 HTML 文件全部链接起来。这样可以在本地查看,也可以用于 Calibre 生成 eBook 文件。
到此,任务完成,问题解决。
虽然这个脚本可以省下不少时间,但毕竟是第一个可用版本,问题不少。比如:1,图片问题,我也不知道 Calibre 生成 eBook 的时候为什么不能抓到远程图片,看样子接下来需要将图片也下载到本地才行;2,再比如有人反映不喜欢倒着读,其实我也不怎么喜欢,到时候再加个开关好了。
当然,如果您乐意提供帮助,我非常欢迎,可以去 Github 找到这个项目。
利益声明:请留意,我于 2006 至 2010 年期间在新浪网工作,工作内容与新浪博客有关。我目前仍受雇于新浪公司,仍从新浪公司按月领取薪水。
大鱼是我见过的kindle user里给kindle折腾和使用率最高的了。。。我自诩为重度用户,用着狗耳朵等一系列推送服务,也时不时隔三差五来折腾下各种服务,还是觉得没你使用率高。。
@f
Kindle 是电子书,所以它是用来阅读的。是否用的频繁,在于你用它阅读了多少东西,不在于折腾了多大动静呀。
你好,Calibre生成ebook时,不能转换远程图片,这个问题不知道有没有解决?看不了图片!!谢谢!